ChⅥ 数据库应用编程
数据库连接技术
ODBC
ODBC(Open Database Connectivity)是 Microsoft 在 1990 年代初提出的数据库访问标准 API。它以 SQL 作为主要访问语言,通过统一接口屏蔽不同 DBMS 的差异,使应用程序可以在不重写大量代码的情况下访问多种数据库。
ODBC 驱动程序是面向特定 DBMS 的实现库。应用程序调用 ODBC API,ODBC Driver Manager 再将请求转发给对应数据库驱动,最终由驱动与 DBMS 通信。
ODBC 的主要作用:
- 提供一套公共的、基于 SQL 的数据库访问 API
- 允许同一套应用程序代码访问不同数据库系统
- 将应用程序与具体 DBMS 解耦,提高数据库访问层的可移植性
- 支持在一个应用程序中访问多个数据源
JDBC
JDBC(Java Database Connectivity)是 Java 平台提供的数据库访问 API。它通过 java.sql 包定义连接、执行 SQL、读取结果集等接口,并由具体数据库厂商提供 JDBC Driver 实现。Java 程序通过 JDBC Driver 与 DBMS 通信。
JDBC 程序访问数据库的一般步骤:
- 导入
java.sql包 - 加载并注册驱动程序
- 创建
Connection对象 - 创建
Statement或PreparedStatement对象 - 执行 SQL 语句
- 使用
ResultSet读取查询结果 - 依次关闭
ResultSet、Statement、Connection
// 实际开发中,密码不应该明文存储。通常应使用配置文件、环境变量或密钥管理服务。public class ProcessAccountData { private static final String SQL_URL = "jdbc:mysql://localhost:3306/free_chat?serverTimezone=GMT&useSSL=false&allowPublicKeyRetrieval=true"; private static final String DB_USER = "root"; private static final String DB_PASSWORD = "<password>"; /** * @apiNote 从数据库读取账号数据,写入 validUsers * @param validUsers 要写入账号数据的 HashMap * @throws IOException */ public void readAccountFile(ConcurrentHashMap<String, User> validUsers) { try { Class.forName("com.mysql.cj.jdbc.Driver"); } catch (ClassNotFoundException e) { e.printStackTrace(); return; } try (Connection conn = DriverManager.getConnection(SQL_URL, DB_USER, DB_PASSWORD); Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("SELECT account, pwd FROM accounts")) { while (rs.next()) { User user = new User(rs.getString("account"), rs.getString("pwd")); validUsers.put(rs.getString("account"), user); } } catch (SQLException e) { e.printStackTrace(); } } /** * @apiNote 注册时,将 userId 和 pwd 写入数据库 * @param userId 用户 id * @param pwd 用户密码 * @throws IOException */ public void writeAccountFile(String userId, String pwd) { String sql = "INSERT INTO accounts (account, pwd) VALUES (?, ?)"; try (Connection conn = DriverManager.getConnection(SQL_URL, DB_USER, DB_PASSWORD); PreparedStatement pstmt = conn.prepareStatement(sql)) { pstmt.setString(1, userId); pstmt.setString(2, pwd); pstmt.executeUpdate(); } catch (SQLException e) { e.printStackTrace(); } }}Servlet
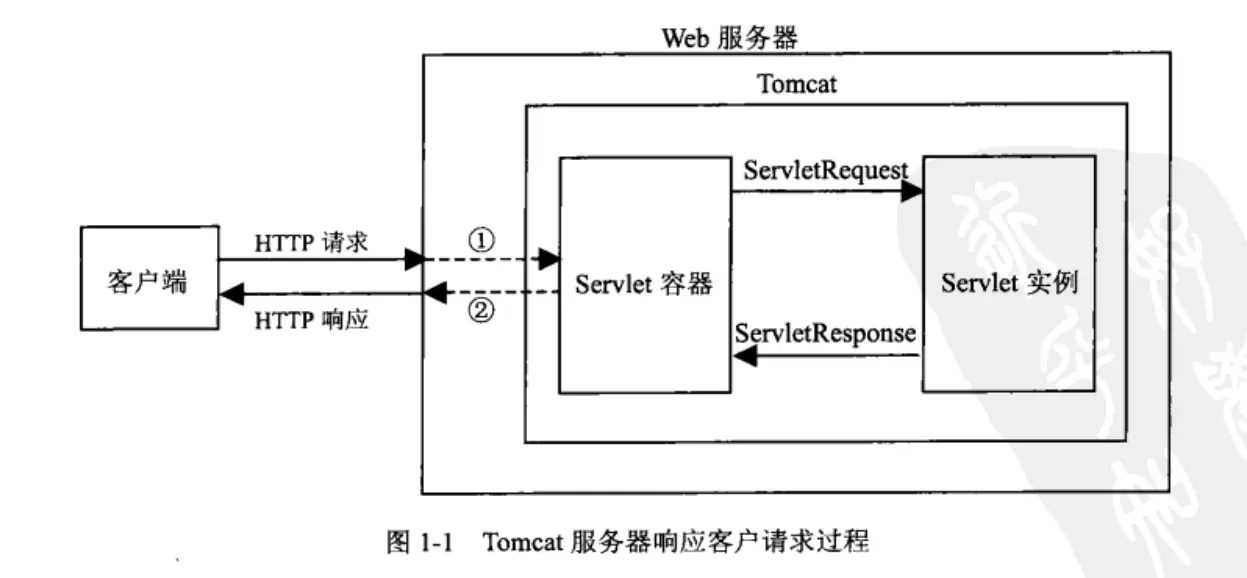
Servlet 是 Java Web 技术的核心组件。它运行在服务器端,由 Web 容器管理,用于处理来自客户端的 HTTP 请求,并生成动态响应。Servlet 曾属于 Java EE 规范;Java EE 8 之后,相关规范转交给 Eclipse 基金会,并更名为 Jakarta EE。
Servlet 的关键点:
- 生命周期:由 Web 容器负责加载、实例化、初始化、处理请求和销毁,核心方法包括
init()、service()和destroy()。 - 请求处理:Servlet 可以处理 GET、POST 等 HTTP 请求。请求和响应分别封装为
HttpServletRequest和HttpServletResponse。 - 线程安全:Servlet 容器通常为多个请求创建多个线程,并共享同一个 Servlet 实例,因此 Servlet 中的可变共享状态需要格外谨慎。
- 配置和上下文:Servlet 可通过
ServletConfig和ServletContext访问初始化参数和应用级上下文。 - 会话管理:Servlet 通过
HttpSession管理与用户相关的会话状态。 - 过滤器和监听器:Servlet API 提供
Filter和Listener,用于拦截请求/响应或监听应用事件。
MyBatis
MyBatis 是一个持久层框架,支持自定义 SQL、存储过程和高级映射。它封装了大部分 JDBC 样板代码,包括参数设置、结果集遍历和对象映射。开发者可以通过 XML 或注解配置 SQL,并将查询结果映射为 Java 对象。
MyBatis 通常被视为介于全自动 ORM 框架和原生 JDBC 之间的方案:它不像 Hibernate 那样强约束对象关系映射,也不需要开发者手动处理所有 JDBC 细节。
MyBatis 的优点:
- 支持自定义 SQL、存储过程、及高级映射
- 自动完成 SQL 参数设置
- 自动解析和封装结果集
- 支持通过 XML 或注解进行配置和映射
- 数据源连接信息可通过配置文件管理
JSP
JSP 全称为 Java Server Pages,即 Java 服务器页面。JSP 是一种以文本为基础的动态网页技术,特点是可以在 HTML 中嵌入 Java 代码。
从运行机制看,JSP 可以理解为 Servlet 的一种特殊形式:JSP 页面在编译后会转换成 Servlet,再由 Web 容器执行。相比直接编写 Servlet,JSP 更适合描述页面结构;Servlet 更适合处理请求控制和业务调度。
JSP 内置了 9 个对象:out、session、response、request、config、page、application、pageContext、exception。
SSM 典型 Java Web 开发架构
- JSP/HTML 页面发送请求
- Controller 层接收用户请求,进行响应的流程处理
- Service 层完成具体的业务逻辑
- DAO(Data Access Object)层对数据库进行操作
- 数据库
数据库存储过程
存储过程(Stored Procedure)是存储在数据库服务器端的一组 SQL 或过程化语句。它通常用于封装会被重复执行的数据库逻辑。客户端只需要指定存储过程名称并传入参数,数据库即可执行相应逻辑。
在 PostgreSQL 中,历史上常用 CREATE FUNCTION 编写带过程逻辑的数据库函数;PostgreSQL 11 之后也支持使用 CREATE PROCEDURE 创建真正意义上的存储过程。
优点
- 减少客户端与数据库之间的网络通信量
- 已编译或已解析的数据库端逻辑通常执行更快
- 可以复用复杂的数据处理逻辑
- 降低业务程序与数据库操作细节之间的耦合
- 降低应用层重复实现复杂 SQL 逻辑的成本
- 可以隐藏部分数据库元信息
- 有助于集中控制权限,增强数据库安全性
缺点
- SQL 偏声明式查询,存储过程偏过程式编程;复杂业务逻辑在存储过程中可能难以维护。
- 如果参数或返回数据结构变化,通常需要同时修改存储过程和调用它的应用程序代码。
- 调试体验通常弱于通用编程语言,开发和排错成本较高。
- 不同 DBMS 的过程语言差异较大,可移植性较差。
-- 创建函数CREATE [ OR REPLACE ] FUNCTION name([ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ])[ RETURNS retype | RETURNS TABLE ( column_name column_type [, ...] ) ]AS $$ -- $$ 用于声明函数体的开始DECLARE -- 声明段BEGIN -- 函数体语句END;$$ LANGUAGE lang_name; -- LANGUAGE 后面指明所用的过程语言-- 删除函数DROP FUNCTION [ IF EXISTS ] name( [ [ argmode ] [ argname ] argtype [, ...] ] )[ CASCADE | RESTRICT ];主要参数:
name:要创建或删除的函数名。OR REPLACE:如果同名函数已存在,则覆盖定义。argmode:参数模式,可为IN、OUT、INOUT或VARIADIC,默认是IN。argname:形式参数名称。RETURNS:返回值类型。RETURNS TABLE:返回表结构。CASCADE:级联删除依赖于该函数的对象,如触发器。RESTRICT:如果存在依赖对象,则拒绝删除;这是默认行为。
PL/pgSQL Syntax
变量声明
变量声明写在 DECLARE 段中,基本格式为:variable_name data_type;
如果声明变量为记录类型,可以使用 RECORD:variable_name RECORD;
RECORD 不是固定结构的数据类型,而是一个可以在运行时承载查询结果行的占位类型。DECLARE counter integer; rec RECORD;
条件语句
IF condition THEN statement;END IF;IF condition THEN statement;ELSE statement;END IF;IF condition1 THEN statement;ELSIF condition2 THEN statement;ELSE statement;END IF;循环语句
LOOP statement;END LOOP [label];LOOP i = i + 1; EXIT WHEN i > 10;END LOOP;LOOP i = i + 1; EXIT WHEN i > 100; CONTINUE WHEN i < 50; j = j + 1;END LOOP;WHILE condition LOOP statement;END LOOP;FOR i IN 1..10 LOOP RAISE NOTICE 'i = %', i;END LOOP;CREATE FUNCTION out_record() RETURNS RECORD AS $$DECLARE rec RECORD;BEGIN FOR rec IN SELECT * FROM student LOOP RAISE NOTICE '学生数据: %, %', rec.studentID, rec.studentName; END LOOP; RETURN rec;END;$$ LANGUAGE plpgsql;Return Type
在 SQL 和 PL/pgSQL 中,函数可以返回以下几种类型的值:
标量(Scalar):最简单的返回类型,可以是任意基本数据类型,如
INTEGER、VARCHAR、BOOLEAN等。CREATE FUNCTION add_one(INTEGER) RETURNS INTEGER AS $$BEGIN RETURN $1 + 1;END;$$ LANGUAGE plpgsql;记录(Record):函数可以返回一个完整记录。记录结构通常与已有表或查询结果一致。
CREATE FUNCTION get_employee(INTEGER) RETURNS employee AS $$DECLARE rec employee%ROWTYPE;BEGIN SELECT * INTO rec FROM employee WHERE id = $1; RETURN rec;END;$$ LANGUAGE plpgsql;表(Table):函数可以返回一个表,即多条记录。这个表可以有自定义结构,也可以与已有表一致。
CREATE FUNCTION get_employees() RETURNS TABLE(id INTEGER, name VARCHAR) AS $$BEGIN RETURN QUERY SELECT id, name FROM employee;END;$$ LANGUAGE plpgsql;触发器(Trigger):在 PostgreSQL 中,触发器函数必须声明为返回
TRIGGER。CREATE FUNCTION check_update() RETURNS TRIGGER AS $$BEGIN IF NEW.updated_at < OLD.updated_at THEN RAISE EXCEPTION 'Update timestamp must be newer'; END IF; RETURN NEW;END;$$ LANGUAGE plpgsql;复合类型(Composite Type):函数可以返回一个自定义复合类型。
CREATE TYPE my_type AS (f1 integer, f2 text);CREATE FUNCTION return_compound() RETURNS my_type AS $$BEGIN RETURN ROW(1, 'test')::my_type;END;$$ LANGUAGE plpgsql;Void:如果函数不需要返回任何值,可以使用
VOID类型。CREATE FUNCTION log_message(text) RETURNS VOID AS $$BEGIN RAISE NOTICE '%', $1;END;$$ LANGUAGE plpgsql;
Examples
- 统计学生表中有多少条记录。
CREATE OR REPLACE FUNCTION count_records()RETURNS integer AS $$DECLARE student_count integer;BEGIN SELECT count(*) INTO student_count FROM student; -- INTO 用于将查询结果赋值给变量 RETURN student_count;END;$$ LANGUAGE plpgsql;SELECT count_records();如果
grade >= 60,视为该学生取得相应课程学分。编写 SQL 统计每个学生取得的总学分,结果包含学号、姓名、总学分。Course(courseid,coursename,credit)
Grade(gradeid,studentid,courseid,grade)
Student(studentid,studentname,sex,age)
CREATE OR REPLACE FUNCTION get_credit() RETURNS TABLE( vsid CHAR, vsname VARCHAR, vscredit BIGINT )AS $vscredit$BEGIN RETURN QUERY SELECT c.studentid AS vsid, c.studentname AS vsname, SUM(a.credit) AS vscredit FROM course AS a JOIN grade AS b ON a.courseid = b.courseid JOIN student AS c ON b.studentid = c.studentid WHERE b.grade >= 60 GROUP BY c.studentid, c.studentname;END;$vscredit$ LANGUAGE plpgsql;SELECT * FROM get_credit();- 创建一个名为
add_data(a, b, c)的存储过程,实现a + b运算,并将结果放入c。
CREATE OR REPLACE PROCEDURE add_data(a integer, b integer, INOUT c integer)AS $$BEGIN c = a + b;END;$$ LANGUAGE plpgsql;数据库触发器
触发器是定义在表或视图上的特殊数据库对象。它由指定操作事件自动触发执行,可用于实现比约束更复杂的数据完整性检查和业务规则。
按照触发粒度,触发器可以分为:
- 语句级触发器:每条触发语句只执行一次。
- 行级触发器:被影响的每一行都会执行一次。
常用触发器上下文变量:
NEW:RECORD类型。对于行级INSERT或UPDATE,保存新数据行;对于语句级触发器,其值为NULL。OLD:RECORD类型。对于行级DELETE或UPDATE,保存旧数据行;对于语句级触发器,其值为NULL。TG_OP:text类型,值为INSERT、UPDATE或DELETE,表示触发当前触发器的操作。INSTEAD OF触发器:常用于视图。事件发生时执行触发器逻辑,而不是执行原始 SQL 操作。
创建触发器的一般步骤:
- 确认触发器依附的表或视图存在。
- 创建触发器函数,返回类型为
TRIGGER。 - 创建触发器,将事件、触发时机和触发函数绑定起来。
-- 创建表CREATE TABLE stu_score ( sid character(10) NOT NULL, cid character(10) NOT NULL, score numeric(5, 1), CONSTRAINT stu_score_pkey PRIMARY KEY (sid, cid));CREATE TABLE audit_score ( username character(20), -- 用户名 sid character(10), cid character(10), updatetime timestamp, -- 修改时间 oldscore numeric(5, 1), -- 修改前的成绩 newscore numeric(5, 1) -- 修改后的成绩);-- 创建触发器函数CREATE OR REPLACE FUNCTION score_audit()RETURNS TRIGGERAS $score_audits$BEGIN IF TG_OP = 'DELETE' THEN INSERT INTO audit_score VALUES (user, OLD.sid, OLD.cid, now(), OLD.score, NULL); RETURN OLD; ELSIF TG_OP = 'UPDATE' THEN INSERT INTO audit_score VALUES (user, OLD.sid, OLD.cid, now(), OLD.score, NEW.score); RETURN NEW; ELSIF TG_OP = 'INSERT' THEN INSERT INTO audit_score VALUES (user, NEW.sid, NEW.cid, now(), NULL, NEW.score); RETURN NEW; END IF; RETURN NULL;END;$score_audits$ LANGUAGE plpgsql;-- 创建触发器CREATE TRIGGER score_audit_triggerAFTER INSERT OR UPDATE OR DELETE ON stu_scoreFOR EACH ROW EXECUTE FUNCTION score_audit();-- 修改触发器名称ALTER TRIGGER score_audit_trigger ON stu_score RENAME TO score_audit_trig;-- 删除触发器DROP TRIGGER IF EXISTS score_audit_trig ON stu_score CASCADE;数据库游标
游标是一种用于逐行处理查询结果的数据库对象。它与一条查询语句关联,内部保存查询结果和当前位置指针,适合在过程语言中逐条读取结果集。-- 声明游标cur_student CURSOR FOR SELECT * FROM student;cur_student_one CURSOR (key integer) IS SELECT * FROM student WHERE sid = key;-- 打开游标OPEN cur_vars1 FOR SELECT * FROM student WHERE sid = mykey;OPEN cur_vars1 FOR EXECUTE 'SELECT * FROM ' || quote_ident($1);OPEN cur_student;OPEN cur_student_one('20160230302001');-- 使用游标提取值FETCH cur_vars1 INTO rowvar; -- rowvar 为行变量FETCH cur_student INTO sid, sname, sex;-- 关闭游标CLOSE cursor_name;